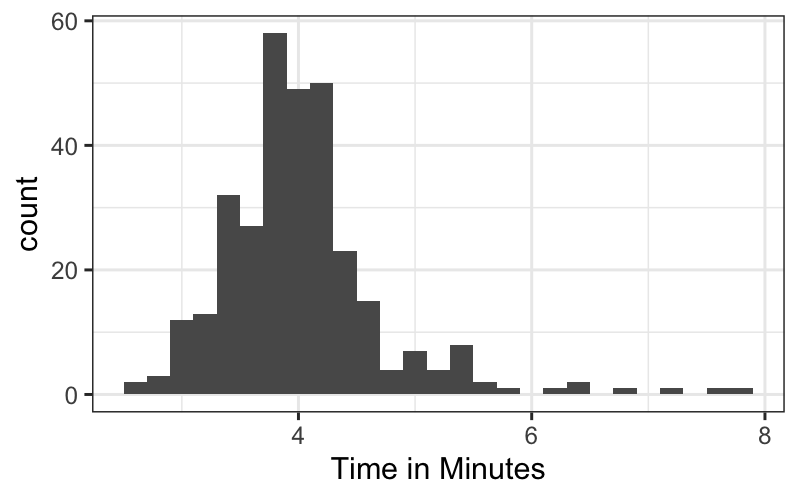
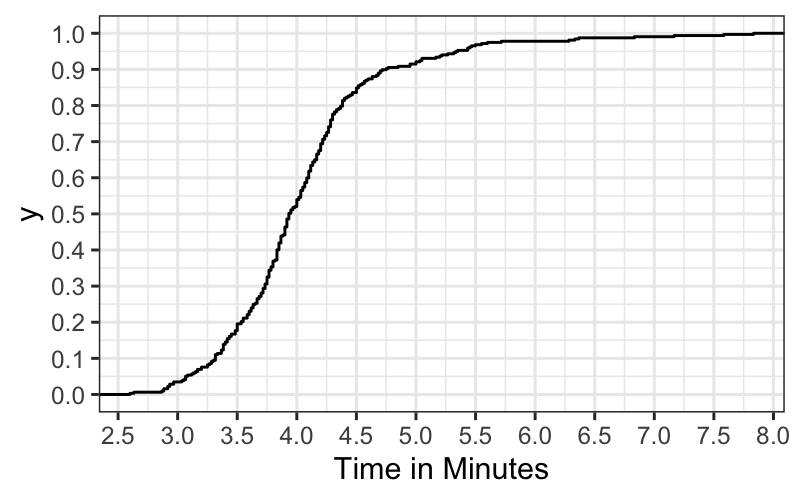
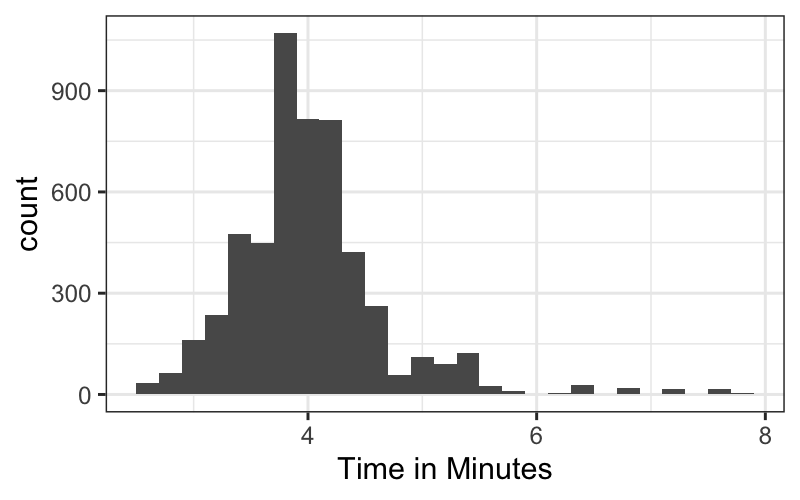
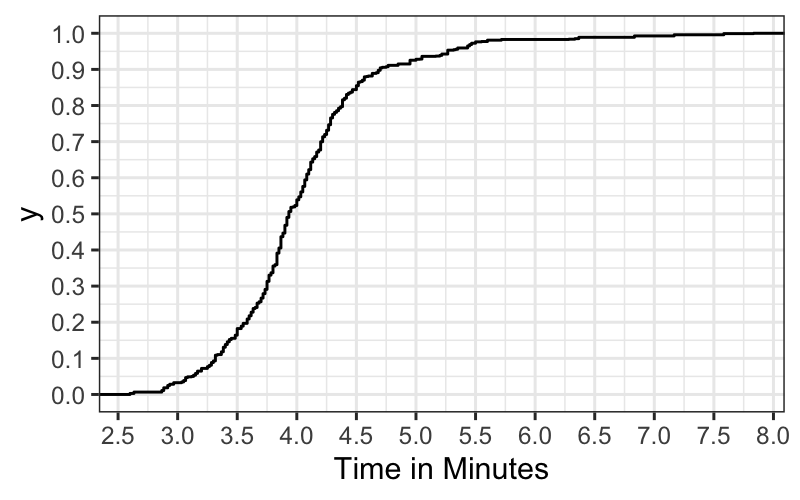
billboard_tidy = read_csv("https://github.com/hadley/tidy-data/raw/master/data/billboard.csv")
## Rows: 317 Columns: 83
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (3): artist.inverted, track, genre
## dbl (66): year, x1st.week, x2nd.week, x3rd.week, x4th.week, x5th.week, x6th...
## lgl (11): x66th.week, x67th.week, x68th.week, x69th.week, x70th.week, x71st...
## date (2): date.entered, date.peaked
## time (1): time
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
billboard_standard = read.csv("https://github.com/hadley/tidy-data/raw/master/data/billboard.csv", stringsAsFactors = FALSE)
billboard_tidy
## # A tibble: 317 × 83
## year artis…¹ track time genre date.ent…² date.pea…³ x1st.…⁴ x2nd.…⁵ x3rd.…⁶
## <dbl> <chr> <chr> <tim> <chr> <date> <date> <dbl> <dbl> <dbl>
## 1 2000 Destin… Inde… 03:38 Rock 2000-09-23 2000-11-18 78 63 49
## 2 2000 Santana Mari… 04:18 Rock 2000-02-12 2000-04-08 15 8 6
## 3 2000 Savage… I Kn… 04:07 Rock 1999-10-23 2000-01-29 71 48 43
## 4 2000 Madonna Music 03:45 Rock 2000-08-12 2000-09-16 41 23 18
## 5 2000 Aguile… Come… 03:38 Rock 2000-08-05 2000-10-14 57 47 45
## 6 2000 Janet Does… 04:17 Rock 2000-06-17 2000-08-26 59 52 43
## 7 2000 Destin… Say … 04:31 Rock 1999-12-25 2000-03-18 83 83 44
## 8 2000 Iglesi… Be W… 03:36 Latin 2000-04-01 2000-06-24 63 45 34
## 9 2000 Sisqo Inco… 03:52 Rock 2000-06-24 2000-08-12 77 66 61
## 10 2000 Lonest… Amaz… 04:25 Coun… 1999-06-05 2000-03-04 81 54 44
## # … with 307 more rows, 73 more variables: x4th.week <dbl>, x5th.week <dbl>,
## # x6th.week <dbl>, x7th.week <dbl>, x8th.week <dbl>, x9th.week <dbl>,
## # x10th.week <dbl>, x11th.week <dbl>, x12th.week <dbl>, x13th.week <dbl>,
## # x14th.week <dbl>, x15th.week <dbl>, x16th.week <dbl>, x17th.week <dbl>,
## # x18th.week <dbl>, x19th.week <dbl>, x20th.week <dbl>, x21st.week <dbl>,
## # x22nd.week <dbl>, x23rd.week <dbl>, x24th.week <dbl>, x25th.week <dbl>,
## # x26th.week <dbl>, x27th.week <dbl>, x28th.week <dbl>, x29th.week <dbl>, …
billboard_standard[1:10, 1:8]
## year artist.inverted track time genre
## 1 2000 Destiny's Child Independent Women Part I 3:38 Rock
## 2 2000 Santana Maria, Maria 4:18 Rock
## 3 2000 Savage Garden I Knew I Loved You 4:07 Rock
## 4 2000 Madonna Music 3:45 Rock
## 5 2000 Aguilera, Christina Come On Over Baby (All I Want Is You) 3:38 Rock
## 6 2000 Janet Doesn't Really Matter 4:17 Rock
## 7 2000 Destiny's Child Say My Name 4:31 Rock
## 8 2000 Iglesias, Enrique Be With You 3:36 Latin
## 9 2000 Sisqo Incomplete 3:52 Rock
## 10 2000 Lonestar Amazed 4:25 Country
## date.entered date.peaked x1st.week
## 1 2000-09-23 2000-11-18 78
## 2 2000-02-12 2000-04-08 15
## 3 1999-10-23 2000-01-29 71
## 4 2000-08-12 2000-09-16 41
## 5 2000-08-05 2000-10-14 57
## 6 2000-06-17 2000-08-26 59
## 7 1999-12-25 2000-03-18 83
## 8 2000-04-01 2000-06-24 63
## 9 2000-06-24 2000-08-12 77
## 10 1999-06-05 2000-03-04 81
summary(billboard_tidy$date.entered)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## "1999-06-05" "2000-02-05" "2000-04-29" "2000-05-03" "2000-08-12" "2000-12-30"
summary(billboard_standard$date.entered)
## Length Class Mode
## 317 character character